InterHand2.6M dataset
Our new Re:InterHand dataset has been released, which has much more diverse image appearances with more stable 3D GT. Check it out at here!
Quick visualizations


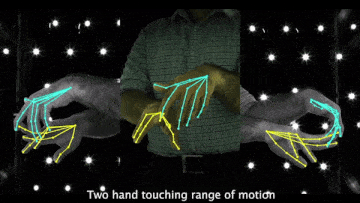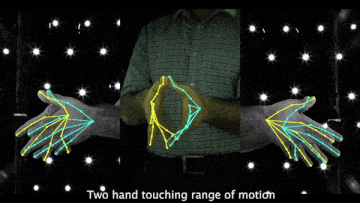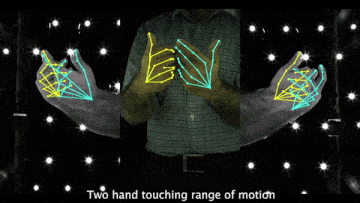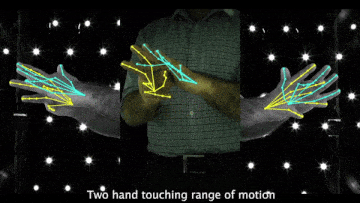
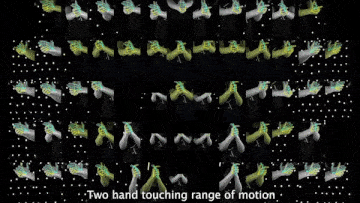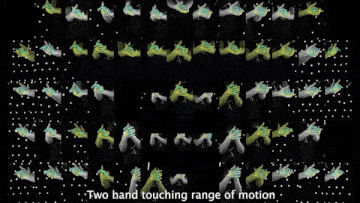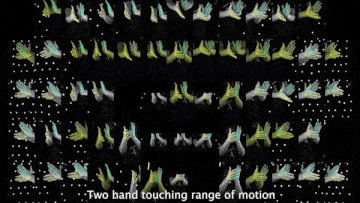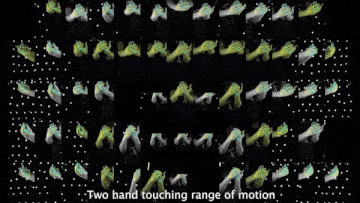

Above demo videos have low-quality frames because of the compression for the README upload.

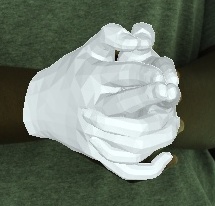
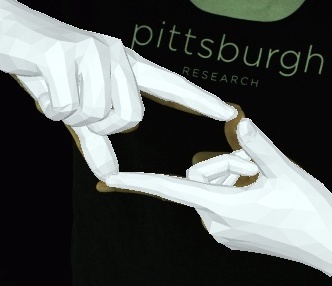
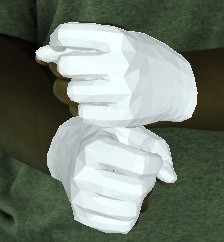

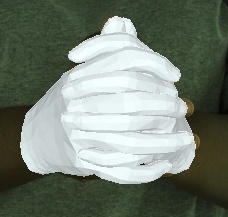
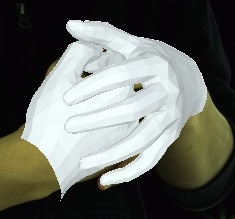

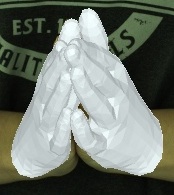

- Videos of 3D joint coordinates (from joint_3d.json) from the 30 fps split: [single hand] [two hands].
- Videos of MANO fittings from the 30 fps split: [single hand] [two hands].
News
- 2023.05.05. Visualized videos are available.
- 2021.03.22. Finally, InterHand2.6M v1.0, which includes all images of 5 fps and 30 fps version, is released! 🎉 This is the dataset used in InterHand2.6M paper.
- 2020.11.26. Fitted MANO parameters are updated to the better ones (fitting error is about 5 mm). Also, reduced to much smaller file size by providing parameters fitted to the world coordinates (independent on the camera view).
- 2020.10.7. Fitted MANO parameters are available! They are obtained by NeuralAnnot.
Introduction
- This is an official release of InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image (ECCV 2020).
- Our InterHand2.6M dataset is the first large-scale real-captured dataset with accurate GT 3D interacting hand poses.
- Specifications of InterHand2.6M are as below.
Train set
* Train (H): 142,231 single hand frames / 386,251 interacting hand frames / 528,482 total frames
* Train (M): 594,189 single hand frarmes / 314,848 interacting hand frames / 909,037 total frames
* Train (H+M): 687,548 single hand frames / 673,514 interacting hand frames / 1,361,062 total frames
Validation set
* Val (M): 234,183 single hand frames / 145,942 interacting hand frames / 380,125 total frames
Test set
* Test (H): 33,665 single hand frames / 87,908 interacting hand frames / 121,573 total frames
* Test (M): 455,303 single hand frames / 272,284 interacting hand frames / 727,587 total frames
* Test (H+M): 488,968 single hand frames / 360,192 interacting hand frames / 849,160 total frames
Total set
* InterHand2.6M: 1,410,699 single hand frames / 1,179,648 interacting hand frames / 2,590,347 total frames
Download
Images
- Images (v1.0)
- Instead of manually downloading files from the above link, you can run a download script.
- To verify downloaded files using
md5sum, runpython verify_download.py. - To unzip images, run
sh unzip.sh. - All image files take 80 GB.
Annotations
- Annotations (v1.0). H+M in the paper
- Annotation IDs of human annotation (H) train set and human annotation (M) test set
- Camera positions visualization codes are available in here
Directory
The ${ROOT} is described as below.
${ROOT}
|-- images
| |-- train
| | |-- Capture0 ~ Capture26
| |-- val
| | |-- Capture0
| |-- test
| | |-- Capture0 ~ Capture7
|-- annotations
| |-- skeleton.txt
| |-- subject.txt
| |-- train
| |-- val
| |-- test
- Note: train/Capture10-26 and test/Capture2-7 contain frames less than 5 fps (or 30 fps if you downloaded the 30 fps version) due to multiple rounds of image dumping.
Annotation files
- Using Pycocotools for the data load is recommended. Run
pip install pycocotools. skeleton.txtcontains information about hand hierarchy (keypoint name, keypoint index, keypoint parent index).subject.txtcontains information about the subject (subject_id, subject directory, subject gender).
There are four .json files.
InterHand2.6M_$DB_SPLIT_data.json: dict
|-- 'images': [image]
|-- 'annotations': [annotation]
image: dict
|-- 'id': int (image id)
|-- 'file_name': str (image file name)
|-- 'width': int (image width)
|-- 'height': int (image height)
|-- 'capture': int (capture id)
|-- 'subject': int (subject id)
|-- 'seq_name': str (sequence name)
|-- 'camera': str (camera name)
|-- 'frame_idx': int (frame index)
annotation: dict
|-- 'id': int (annotation id)
|-- 'image_id': int (corresponding image id)
|-- 'bbox': list (bounding box coordinates. [xmin, ymin, width, height])
|-- 'joint_valid': list (can this annotaion be use for hand pose estimation training and evaluation? 1 if a joint is annotated and inside of image. 0 otherwise. this is based on 2D observation from the image.)
|-- 'hand_type': str (one of 'right', 'left', and 'interacting')
|-- 'hand_type_valid': int (can this annotation be used for handedness estimation training and evaluation? 1 if hand_type in ('right', 'left') or hand_type == 'interacting' and np.sum(joint_valid) > 30, 0 otherwise. this is based on 2D observation from the image.)
InterHand2.6M_$DB_SPLIT_camera.json
|-- str (capture id)
| |-- 'campos'
| | |-- str (camera name): [x,y,z] (camera position)
| |-- 'camrot'
| | |-- str (camera name): 3x3 list (camera rotation matrix)
| |-- 'focal'
| | |-- str (camera name): [focal_x, focal_y] (focal length of x and y axis
| |-- 'princpt'
| | |-- str (camera name): [princpt_x, princpt_y] (principal point of x and y axis)
InterHand2.6M_$DB_SPLIT_joint_3d.json
|-- str (capture id)
| |-- str (frame idx):
| | |-- 'world_coord': Jx3 list (3D joint coordinates in the world coordinate system. unit: milimeter.)
| | |-- 'joint_valid': Jx3 list (1 if a joint is successfully annotated 0 else. Unlike 'joint_valid' of InterHand2.6M_$DB_SPLIT_data.json, it does not consider whether it is truncated in the image space or not.)
| | |-- 'hand_type': str (one of 'right', 'left', and 'interacting'. taken from sequence names)
| | |-- 'seq': str (sequence name)
InterHand2.6M_$DB_SPLIT_MANO_NeuralAnnot.json
|-- str (capture id)
| |-- str (frame idx):
| | |-- 'right'
| | | |-- 'pose': 48 dimensional MANO pose vector in axis-angle representation minus the mean pose.
| | | |-- 'shape': 10 dimensional MANO shape vector.
| | | |-- 'trans': 3 dimensional MANO translation vector in meter unit.
| | |-- 'left'
| | | |-- 'pose': 48 dimensional MANO pose vector in axis-angle representation minus the mean pose.
| | | |-- 'shape': 10 dimensional MANO shape vector.
| | | |-- 'trans': 3 dimensional MANO translation vector in meter unit.
The 3D MANO fits are obtained by NeuralAnnot (https://arxiv.org/abs/2011.11232).
For the MANO mesh rendering, please see https://github.com/facebookresearch/InterHand2.6M/blob/master/MANO_render/render.py
InterHand2.6M in 30 fps
- Above InterHand2.6M is a downsampled version to 5 fps to remove redundancy.
- We additionally release InterHand2.6M in 30 fps for the video-related research.
- It has exactly the same directory structure with that of the InterHand2.6M in 5 fps.
Train set
* Train (H): 142,240 single hand frames / 386,270 interacting hand frames / 528,510 total frames
* Train (M): 3,420,240 single hand frarmes / 1,862,657 interacting hand frames / 5,282,897 total frames
* Train (H+M): 3,513,605 single hand frames / 2,202,883 interacting hand frames / 5,716,488 total frames
Validation set
* Val (M): 1,401,601 single hand frames / 874,448 interacting hand frames / 2,276,049 total frames
Test set
* Test (H): 33,672 single hand frames / 87,919 interacting hand frames / 121,591 total frames
* Test (M): 2,725,911 single hand frames / 1,629,860 interacting hand frames / 4,355,771 total frames
* Test (H+M): 2,759,583 single hand frames / 1,717,779 interacting hand frames / 4,477,362 total frames
Total set
* InterHand2.6M: 7,674,789 single hand frames / 4,795,110 interacting hand frames / 12,469,899 total frames
Download
Images
- Images (v1.0)
- Instead of manually downloading files from the above link, you can run a download script.
- To verify downloaded files using
md5sum, runpython verify_download.py. - To unzip images, run
sh unzip.sh. - All image files take 365 GB.
Annotations
- Annotations (v1.0). H+M in the paper
- Annotation IDs of human annotation (H) train set and human annotation (M) test set
- Camera positions visualization codes are available in here
A Baseline for 3D Interacting Hand Pose Estimation (InterNet)
- Go to Github
Contact
If you meet any problems, please send an e-mail to mks0601(at)gmail.com
Reference
@InProceedings{Moon_2020_ECCV_InterHand2.6M,
author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu},
title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}